 Ce billet fait suite au premier billet traitant du sujet du cloisonnement d’un réseau à l’aide de VRF. Le premier billet avait pour objectif dans présenter la plateforme d’expérimentation que nous avons mis en place. Dans ce billet, nous allons nous intéresser à la configuration basique des équipements Cisco que nous avions à notre disposition. Dans un troisième et dernier billet, je présenterais la configuration du BGP permettant le propagation de routes sélectives entre les différentes VRF.
Ce billet fait suite au premier billet traitant du sujet du cloisonnement d’un réseau à l’aide de VRF. Le premier billet avait pour objectif dans présenter la plateforme d’expérimentation que nous avons mis en place. Dans ce billet, nous allons nous intéresser à la configuration basique des équipements Cisco que nous avions à notre disposition. Dans un troisième et dernier billet, je présenterais la configuration du BGP permettant le propagation de routes sélectives entre les différentes VRF.
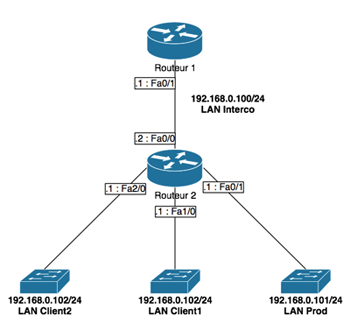
A titre de rappel, je vous renvois vers le précédent billet pour le schéma topologique qui vous permettra de comprendre plus facilement les configurations effectuées ici.
Configuration basique
Afin de pouvoir se retrouver plus facilement parmi tous nos équipements, nous allons paramétrer le nom d’hôte de nos différents équipements conformément au schéma.
ROUTER(config)# hostname ROUTEUR1
ROUTER(config)# hostname ROUTEUR2
Nous allons ensuite configurer les différentes interfaces IP de notre routeur de tête précédemment nommé ROUTEUR1.
ROUTEUR1(config)#interface Fa0/0
ROUTEUR1(config-if)#no ip address
ROUTEUR1(config-if)#shutdown
ROUTEUR1(config-if)#interface Fa0/1
ROUTEUR1(config-if)# ip address 192.168.100.1 255.255.255.0
ROUTEUR1(config-if)#exit
Nous allons ensuite configurer les routes statiques vers les réseaux raccordés directement sur notre second routeur. Il serait possible d’utiliser un protocole de routage mais par simplicité, nous avons choisi d’implémenter des routes statiques.
ROUTEUR1(config)# ip classless
ROUTEUR1(config)# ip route 192.168.0.101.0 255.255.255.0 192.168.100.2
ROUTEUR1(config)# ip route 192.168.0.102.0 255.255.255.0 192.168.100.2
ROUTEUR1(config)# ip route 192.168.0.103.0 255.255.255.0 192.168.100.2
La configuration de ce premier routeur se résume à ces commandes simples. Ce routeur est essentiellement un routeur témoin qui nous permettra de valider nos tests.
Configuration des VRF
Nous allons ensuite nous attaquer à la configuration des VRF sur notre second routeur. Pour rappel, les VRF sont des instances de tables de routage. Nous allons créer une VRF par zone de notre schéma. Nous en avons donc distingué 5 : client1, client2, prod et interco. Chaque zone aura donc sa propre VRF ce qui nous permettra d’avoir un cloisonnement finement paramétrable.
Tout d’abord, nous allons donc créer les VRF. Nous attribuerons un « Route Distinguisher » ou RD à chaque VRF. Un RD est un identifiant unique permettant d’identifier les routes associées à une VRF. Nous nous baserons sur ce critère lorsque nous ferons de la propagation de routes entre les différentes VRF.
ROUTEUR2(config)# ip vrf client1
ROUTEUR2(config-vrf)# rd 200:1
ROUTEUR2(config)# ip vrf client2
ROUTEUR2(config-vrf)# rd 300:1
ROUTEUR2(config)# ip vrf prod
ROUTEUR2(config-vrf)# rd 100:1
ROUTEUR2(config)# ip vrf interco
ROUTEUR2(config-vrf)# rd 400:1
Une fois toutes les VRF créées, nous allons configurer les différentes interfaces selon le schéma défini préalablement.
ROUTEUR2(config)# interface Fa0/0
ROUTEUR2(config-if)# description OUTBOUND
ROUTEUR2(config-if)# ip vrf forwarding interco
ROUTEUR2(config-if)# ip address 192.168.100.2 255.255.255.0
ROUTEUR2(config)# interface Fa0/1
ROUTEUR2(config-if)# description PROD
ROUTEUR2(config-if)# ip vrf forwarding prod
ROUTEUR2(config-if)# ip address 192.168.101.1 255.255.255.0
ROUTEUR2(config)# interface Fa1/0
ROUTEUR2(config-if)# description CLIENT1
ROUTEUR2(config-if)# ip vrf forwarding client1
ROUTEUR2(config-if)# ip address 192.168.102.1 255.255.255.0
ROUTEUR2(config)# interface Fa2/0
ROUTEUR2(config-if)# description CLIENT2
ROUTEUR2(config-if)# ip vrf forwarding client2
ROUTEUR2(config-if)# ip address 192.168.103.1 255.255.255.0
ROUTEUR2(config)# ip route 0.0.0.0 0.0.0.0 192.168.100.1
Nous avons donc configuré les différentes interfaces, les différentes VRF ainsi que l’association des VRF aux interfaces. Si nous n’avions pas eu suffisamment de ports physiques, il vous est tout à fait possible de créer des sous-interfaces 802.1Q qui fonctionneront de manière identiques aux interfaces physiques.
Dans le prochain billet, je détaillerais la configuration du protocole de routage afin de redistribuer les routes de manière sélective parmi toutes nos VRF.
Articles de la série
- Premier épisode : Introduction de l’architecture
- Troisième épisode : BGP

 Le « Routeur 1 » était le routeur du haut et le « Routeur 2 » était le routeur du bas. Au niveau des switchs, nous n’avons utilisé que celui du bas. Les ports 1 et 2 servaient pour le réseau « Interco ». Les ports 13 à 16 étaient le VLAN de Prod. Les ports 17 à 20 étaient le VLAN Client 1. Les ports 21 à 24 étaient les VLAN Client 2. Le câble permettait de relier le PC de test.
Le « Routeur 1 » était le routeur du haut et le « Routeur 2 » était le routeur du bas. Au niveau des switchs, nous n’avons utilisé que celui du bas. Les ports 1 et 2 servaient pour le réseau « Interco ». Les ports 13 à 16 étaient le VLAN de Prod. Les ports 17 à 20 étaient le VLAN Client 1. Les ports 21 à 24 étaient les VLAN Client 2. Le câble permettait de relier le PC de test.
 Je vous ai déjà fait une
Je vous ai déjà fait une  J’ai déjà eu l’occasion de proposer une classification des différents types de virtualisation lors d’un
J’ai déjà eu l’occasion de proposer une classification des différents types de virtualisation lors d’un 



{kind=link}