 Les performances de sites web sont un sujet très complexe qui peut être abordé sous de nombreux angles. Ce sujet est tout à fait critique du fait que les moteurs de recherche prennent en compte cette métrique pour le référencement des sites. Dans le cas de sites e-commerce, les performances peuvent influer assez fortement le taux de conversion des visites en achat comme l’a montré Amazon.
Les performances de sites web sont un sujet très complexe qui peut être abordé sous de nombreux angles. Ce sujet est tout à fait critique du fait que les moteurs de recherche prennent en compte cette métrique pour le référencement des sites. Dans le cas de sites e-commerce, les performances peuvent influer assez fortement le taux de conversion des visites en achat comme l’a montré Amazon.
Afin d’optimiser les performances d’un site, il est souvent préférable de s’intéresser au code et au fonctionnement interne du site afin de détecter les améliorations possibles. Mais, parfois, pour des raisons diverses et variées, vous n’avez soit pas la possibilité soit pas les connaissances vous permettant de mettre les mains dans le code. C’est à cette situation que nous allons nous intéresser aujourd’hui.
Le concept
L’idée est d’utiliser nginx en tant que serveur HTTP frontal et de le coupler à memcache en tant que système de mémoire cache ultra-rapide. Cette manipulation se déroulera en deux parties. Tout d’abord, il faut configurer nginx pour qu’il aille chercher les pages et contenus statiques dans memcache. Ensuite, il faudra remplir la base de données de memcache en pages HTML et contenu statique.
En réussissant à faire cela, nous allons pouvoir fortement réduire le temps de chargement de chaque page mais aussi accroitre considérablement la quantité de requêtes que notre infrastructure pourra traiter en parallèle. Ceci s’explique assez simplement par le fait qu’il est beaucoup moins couteux d’aller chercher une information en base de données stockée en mémoire que d’exécuter toute une pile applicative interfacée avec une base de données type SQL.
Installation et configuration de memcached
L’installation du démon memache, à savoir memcached, est particulièrement simple. Vous pouvez utiliser votre gestionnaire de paquet préféré. Le fichier de configuration est très simple à utiliser, il suffit d’indiquer la quantité de mémoire que vous souhaitez allouer memcached ainsi que l’IP à laquelle vous l’attacherez.
Dans mon cas, j’ai installé memcached directement sur le serveur frontal et l’ai rendu accessible sur une IP interne firewallée de sorte à ce que seuls les serveurs concernés y aient accès. Vous trouverez un exemple de fichier de configuration ici.
Configuration de nginx
En ce qui concerne la configuration de nginx, vous trouverez un exemple ci-dessous.
[code language= »text »]server {
listen 80;
server_name sitetroprapide.fr;
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
location / {
if ($request_method != GET)
{
return 500;
}
default_type text/html;
add_header "Content" "text/html; charset=utf8";
charset utf-8;
set $memcached_key $http_host$uri;
memcached_pass 10.1.1.1:11211;
error_page 500 404 405 = @bypass;
}
location @bypass {
proxy_pass http://sitetroprapide-prod;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504;
proxy_redirect off;
proxy_buffering off;
client_max_body_size 20M;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}[/code]
Les parties spécifiques à memcache sont les lignes 15 à 17. La ligne 15 avec la directive set est probablement celle qui mérite le plus votre attention. En effet, cette ligne définit la « clé » que nginx ira demander à memcache afin de pour la distribuer aux clients. En fonction des sites que vous souhaitez héberger et du type de contenu, vous devez paramétrer cette ligne de sorte à ce que deux contenus différents n’aient pas la même clé sinon il y aura conflit. La configuration proposé utilisera des clés de type « www.sitetroprapide.fr/ » et « www.sitetroprapide.fr/page-1.html ». La ligne 16 avec la directive memcached_pass correspond au serveur memcache que vous souhaitez utiliser.
La ligne 17 avec la directive error_page permet de renvoyer la requête dont le contenu n’a pas été trouvé dans memcache vers les serveurs applicatifs. Grace à cette directive, vous aurez également la possibilité de générer des erreurs afin d’éviter le cache memcache dans certains cas comme c’est le cas pour les requêtes autres que des GET (cf. le block if à la ligne 8).
Mettre les données dans memcache
Vous l’aurez probablement compris, les étapes proposées plus haut permettent à nginx d’aller chercher du contenu dans memcache mais pas d’en stocker dedans. Afin de mettre les données dans memcache, vous aurez plusieurs solutions.
Tout d’abord, vous pouvez modifier votre site afin qu’il stocke le contenu des pages dans memcache. Cette solution est la plus élégante mais nous force à modifier l’application ce que nous souhaitions éviter depuis le début.
Ensuite, une autre solution est de charger les pages du site dans memcache en utilisant un script externe. C’est la solution que j’ai choisi. Vous trouverez un exemple de script que j’ai développé pour l’occasion en Python. Ce script insère dans memcache toutes les pages qui ont lien à partir de la page d’accueil ainsi que tous les contenus associés. Ce n’est probablement pas un exemple d’élégance pour du développement Python mais ça fait ce que je voulais lui faire faire.
Problématiques
Avant de vous montrer un exemple des bénéfices tirés de cette configuration, il me parait indispensable de parler des problématiques induites.
Lorsque vous chargez une page avec une clé dans memcache, le serveur frontal servira toujours cette page sans jamais aller consulter vos serveurs applicatifs. Cela signifie que si vous servez des pages ayant la même URL que vos utilisateurs soient identifiés ou non, memcache distribuera systématiquement la même page. Dans ce cas-là, il faudra adapter la configuration nginx afin de ne pas aller chercher les informations dans memcache si le cookie d’authentification est présent.
Pour résumer, il ne faut pas perdre de vue ce que fait cette configuration car ce n’est pas une solution miracle. C’est une solution très bien adaptée aux sites tels que des sites d’actualité où seulement une faible proportion des utilisateurs sont identifiés. Elle peut également s’appliquer aux sites de e-commerce afin d’accélérer le chargement des pages pour les nouveaux utilisateurs qui ne se sont pas encore identifiés par contre dès qu’ils s’identifieront, les performances redeviendront standards.
Résultats
Voici deux exemples de graphiques présentant le temps de chargement des pages pour deux sites sur lesquels j’ai implémenté cette configuration. L’amélioration est assez flagrante.
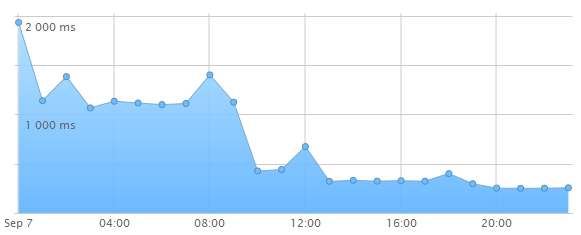
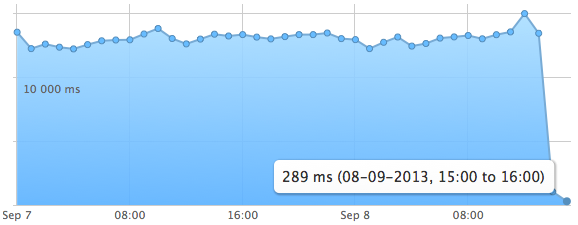
Le script de mise à jour du contenu est exécuté toutes les heures afin d’éviter d’impacter trop fortement les pages non mises en cache. C’est une fréquence de mise à jour acceptable car ce sont des sites relativement peu mis à jour mais cela va dépendre en fonction de cas. Il reste encore des améliorations à faire au niveau du script afin de pouvoir fournir une interface permettant de rafraichir le cache de manière plus automatisée.
Bilan
Pour résumer, il est possible d’accélérer de manière très significative le chargement des pages web en utilisant nginx coupé à memcache. Néanmoins, cette configuration nécessite un mécanisme de chargement des données qui colle le mieux possible au type de site mis en cache. Il faudra donc se pencher sur chaque cas afin d’étudier les possibilités de mise en cache et de trouver la meilleure approche à adopter.


