 Le DNS (Domain Name System) est un service exceptionnellement critique de n’importe quel réseau et de l’Internet. Cette semaine, j’ai eu l’occasion de plancher sur de nombreuses problématiques DNS dans le cadre de la fusion de deux serveurs DNS assez conséquents.
Le DNS (Domain Name System) est un service exceptionnellement critique de n’importe quel réseau et de l’Internet. Cette semaine, j’ai eu l’occasion de plancher sur de nombreuses problématiques DNS dans le cadre de la fusion de deux serveurs DNS assez conséquents.
Dans cet article, je parlerais uniquement de BIND car il s’agit de la référence en terme de serveurs DNS. Je supposerais également que vous utilisez Linux. Et oui, BIND ça fonctionne également sous Windows. Je l’ai même déjà en production sur du Windows… Cela fait un petit pincement au coeur je vous assure.
dig
Le premier outil totalement indispensable est la commande dig. Elle permet d’interroger sélectivement des serveurs DNS. De plus, elle affiche une bonne quantité d’information quant à la requête effectuée. Cette commande sera donc particulièrement utile pour vérifier le bon fonctionnement de votre serveur DNS.
antoine@ks:~$ dig @ns0.infoclip.fr www.infoclip.fr
; <<>> DiG 9.3.4-P1.2 <<>> @ns0.infoclip.fr www.infoclip.fr
; (1 server found)
;; global options: printcmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 47195
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 2, ADDITIONAL: 3
;; QUESTION SECTION:
;www.infoclip.fr. IN A
;; ANSWER SECTION:
www.infoclip.fr. 86400 IN A 217.25.177.18
;; AUTHORITY SECTION:
infoclip.fr. 86400 IN NS ns0.infoclip.fr.
infoclip.fr. 86400 IN NS ns1.infoclip.fr.
;; ADDITIONAL SECTION:
ns0.infoclip.fr. 86400 IN A 217.25.176.28
ns0.infoclip.fr. 86400 IN AAAA 2001:1650:0:1001::2
ns1.infoclip.fr. 86400 IN A 194.29.206.67
;; Query time: 5 msec
;; SERVER: 217.25.176.28#53(217.25.176.28)
;; WHEN: Fri Feb 12 10:23:54 2010
;; MSG SIZE rcvd: 145
host
La commande host est un outil particulièrement utile pour créer des scripts utilisant des informations DNS. Elle permet d’afficher très simplement des informations en rapport avec un nom de domaine telles que les serveurs DNS d’autorité, les MX ou le SOA.
antoine@ks:~$ host -t MX lemonde.fr
lemonde.fr mail is handled by 5 smtp0.lemonde.fr.
lemonde.fr mail is handled by 10 smtp1.lemonde.fr.
antoine@ks:~$ host -t ns lemonde.fr
lemonde.fr name server nsc.bookmyname.com.
lemonde.fr name server nsa.bookmyname.com.
lemonde.fr name server nsb.bookmyname.com.
antoine@ks:~$ host -t soa lemonde.fr
lemonde.fr has SOA record nsa.bookmyname.com. hostmaster.bookmyname.com. 1265963399 43200 3600 604800 3600
named-checkconf
L’outil named-checkconf est fourni avec BIND par défaut mais semble relativement peu connu. Cet utilitaire permet de vérifier la syntaxe d’un fichier de configuration. En sachant que BIND est assez peu tolérant des erreurs, cet outil vous évitera quelques mauvaises surprises.
named-checkconf /etc/named.conf
named-checkzone
Une fois que la configuration de BIND est correcte, il est intéressant de vérifier les zones. Je pense que cette vérification doit être périodique car les erreurs passent facilement inaperçue dans les zones. Cet utilitaire va vérifier la syntaxe de vos zones.
named-checkzone domaine.tld /var/named/domaine.tld
Au final, je pense que ces quelques outils devraient vous permettre de pouvoir mieux diagnostiquer d’éventuels soucis de résolutions de noms de domaine.

 Ce billet fait suite au
Ce billet fait suite au 
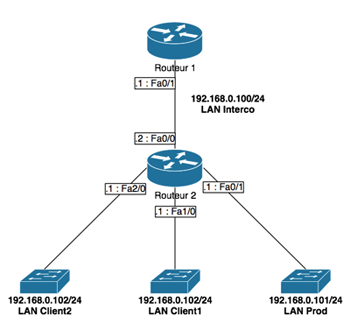
 Le « Routeur 1 » était le routeur du haut et le « Routeur 2 » était le routeur du bas. Au niveau des switchs, nous n’avons utilisé que celui du bas. Les ports 1 et 2 servaient pour le réseau « Interco ». Les ports 13 à 16 étaient le VLAN de Prod. Les ports 17 à 20 étaient le VLAN Client 1. Les ports 21 à 24 étaient les VLAN Client 2. Le câble permettait de relier le PC de test.
Le « Routeur 1 » était le routeur du haut et le « Routeur 2 » était le routeur du bas. Au niveau des switchs, nous n’avons utilisé que celui du bas. Les ports 1 et 2 servaient pour le réseau « Interco ». Les ports 13 à 16 étaient le VLAN de Prod. Les ports 17 à 20 étaient le VLAN Client 1. Les ports 21 à 24 étaient les VLAN Client 2. Le câble permettait de relier le PC de test.

{kind=link}